Incident Process
This document describes our incident handling process for network, operations and security issues.
This document assumes the user has a PagerDuty account and is part of the Analytical Platform team. To use the in Slack features the user must authorise the PagerDuty application in Slack.
1. Confirm that the event constitutes an incident
If this incident constitutes a security breach, you must also report it here
We define an incident as an event which:
- is unplanned
and * impacts end users or our direct users (developers and engineers) * OR: degrades user-facing services * OR: increases risk to production services
If this event does not constitute an incident, the appropriate response is ask a user to raise a support issue or raise a ticket in our GitHub repository, however if the issue is security related, it is raised here.
Once you are confident that you have an incident, declare it as such.
2. Declare the incident
Declaring an incident begins with updating Analytical Platform external status page.
You will be presented with a form for you to complete:
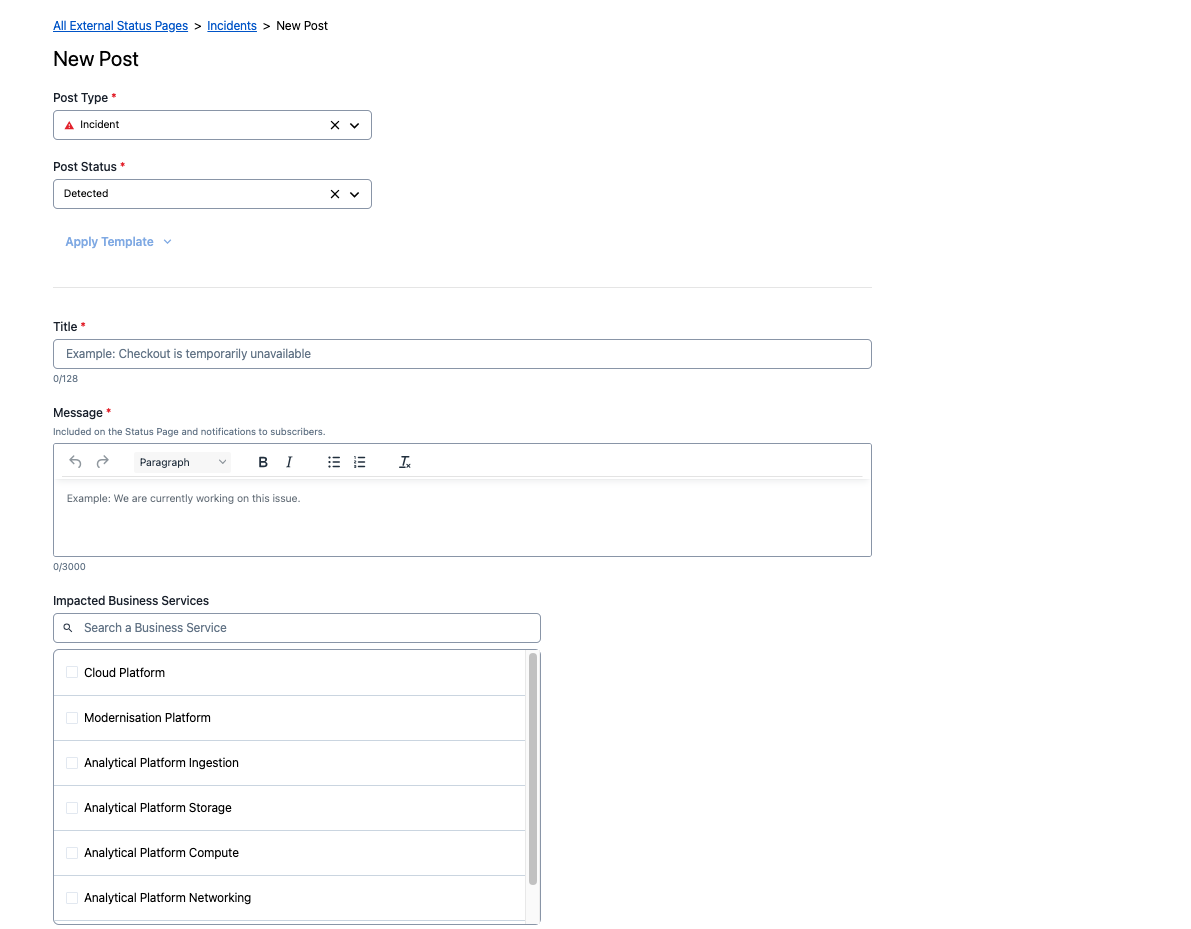
Impacted Service - choose all that apply from the following depending on the type of incident:
- Cloud Platform
- Modernisation Platform
- Analytical Platform Ingestion
- Analytical Platform Storage
- Analytical Platform Compute
- Analytical Platform Networking
- Analytical Platform Identity
Which Impact to assign?
| Impact | Description |
|---|---|
| Major | The whole platform is down or unavailable, all user applications are unavailable |
| Minor | Part of the platform is down or unavailable, some user applications are impacted or unavailable |
| All Good | Incident has been resolved, all service is restored |
Select Time till Next Update. Note that users should be kept regularly updated especially during major outages, and choose accordingly.
Tick the Send update notifications to subscribers box.
Click Post button once you are happy with the form. This will update the external page. The PagerDuty Status Page slack integration will then automatically post the status in the #analytical-platform-support and #ask-data-engineering channels.
3. Managing an Incident
Incident communications must be maintained in a single Slack thread in the main #analytical-platform team channel for maximum visibility.
3.1 Starting a Thread
Incident Slack thread should have a clear starting message and a thread emoji to ensure consistency. Ex: “Airflow Autoscaling Incident :thread:”
3.2 Capturing notes
Please note, communications in the Slack thread could later be used to reconstruct the timeline for post-incident report (if required) therefore it is critical to keep all comms to the single incident thread.
Regular updates to the external status page should be posted to allow stakeholder visibility.
4. Fix the problem
Please bear in mind that not every incident requires the whole team to be involved (even if they all want to join in).
Log a support ticket if necessary.
If the incident cannot be resolved within the team or if the issue lies with a third-party, log a support ticket with the third-party.
For AWS support, log a call in the AWS account affected.
| 3rd Party | How to log a support ticket | Escalation process |
|---|---|---|
| AWS | Creating a support case | On the case, or post in #ext-aws |
5. End the incident
The incident is resolved once the user is no longer facing issues. This may be a temporary fix, in which case an issue should be created to put a permanent fix in place.
Update the external PagerDuty status page with the resolution.
This marks the official end of the incident.
6. Post-incident procedure
After the incident is resolved:
- A new incident report should be created. The notes generated during the incident management in Slack can be used for the incident timeline records.
- A blameless post mortem meeting should be scheduled to identify any processes that need to be improved
- A runbook for how to fix this issue should be published